
The pitch that aged badly
For most of the last decade, the easiest way to put an audience figure against a digital out-of-home screen was to put a small camera on it. A computer-vision module would detect faces in the frame, count them, estimate age and gender, and feed the result back as the audience for whatever creative was playing. The pitch was clean. The number was real-time. The hardware fit on the bezel. For a buyer who wanted DOOH measured like a digital channel, it looked like a fair answer.
In 2026, that pitch has aged badly, and not only because privacy preferences have moved. The legal floor has moved. Under the GDPR, images of identifiable people are personal data, and demographic inference from facial features sits very close to biometric data. Under the EU AI Act, real-time biometric categorisation in publicly accessible spaces is restricted, and demographic inference from a face is exactly the kind of system the Act is concerned about. A network of camera-based audience-measurement devices on screens in a transit station, an airport, a shopping centre, or a high street is a hard system to defend under either framework. Several European markets have effectively closed the door on it. US advertisers running cross-market campaigns are increasingly setting policies that cannot accept camera-based demographic inference even where it remains locally lawful.
The practical question for an operator running a digital signage network, or for an advertiser auditing one, is what to put in place instead. This post sets out four GDPR-safe architectures for DOOH audience measurement that do not use cameras and do not detect faces, with what each one measures well, what it does not, and how they combine. It is aimed at the person specifying or buying measurement, not at the person writing the creative.
What GDPR-safe actually means here
Before working through the architectures, it is worth being precise about the bar. "GDPR-safe" in the context of DOOH measurement means three things, all of which the EU AI Act has now reinforced.
- No biometric capture. The system does not capture images, faces, or any biometric template, and it does not retain anything that could be used to recognise a person again.
- No demographic detection. The system does not infer age, gender, ethnicity, or any other protected category from a person's physical features. This is the part the EU AI Act has tightened most sharply.
- No PII at capture. The system does not collect personal data in the first place. There is no image to store, no face to match, and no identifier that links a measurement to a specific person. This is a stronger position than capturing data and then masking it, because there is nothing identifying to capture in the first place.
An architecture that meets all three is in a clean position under the GDPR, under the EU AI Act, and under the procurement policies that European venues and US advertisers are increasingly applying. The four architectures below all meet that bar. They differ in what they measure and how directly they measure it.
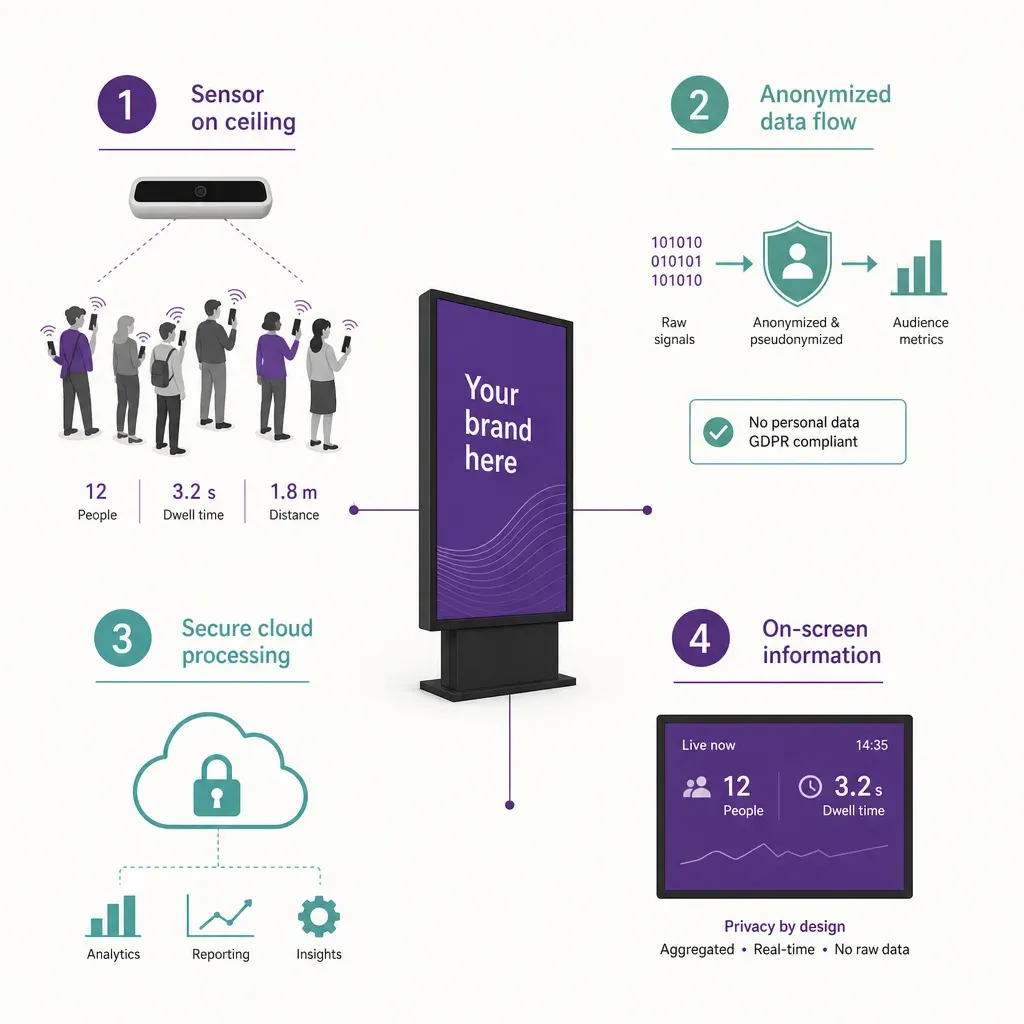
Architecture 1: signal-pattern counting at the screen
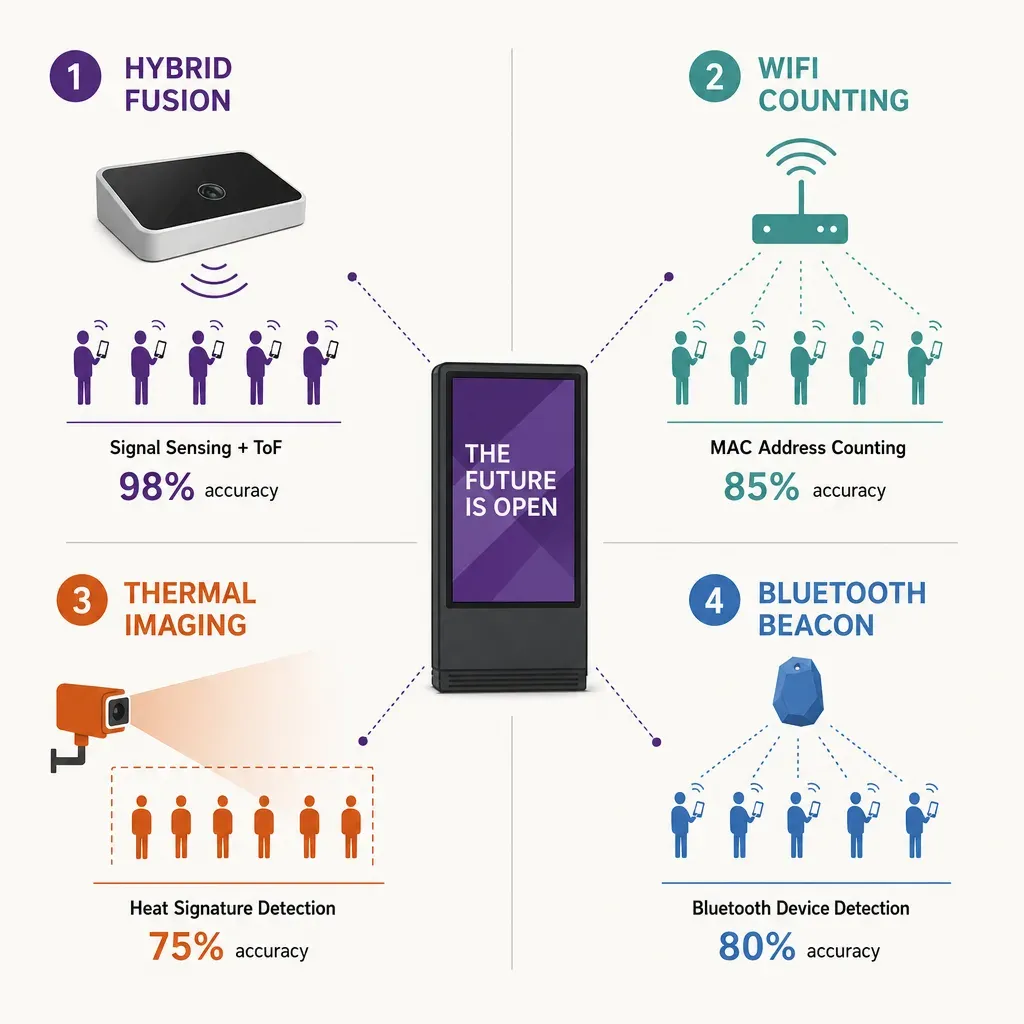
The first architecture puts a sensor near the screen that counts people and measures dwell from the radio signals their phones emit. A modern phone, even in airplane mode, leaks signal: probe requests, Bluetooth advertising packets, and other low-level transmissions that the device makes as part of being a phone. A sensor near the screen can detect those signals, triangulate position to roughly 30 centimetres, and count distinct devices in the screen's coverage zone over time.
What this produces is a useful set of audience metrics at the screen: how many distinct devices entered the zone in a given period, how long each lingered, and how dwell distributes across the day. Group sizing comes from the same signal layer, since a cluster of devices moving together in the zone is a different audience event from a single device passing through. None of this requires an image of the audience or any recognition of who they are.
The privacy posture matters here. A well-implemented signal sensor does not capture MAC addresses by default. The raw radio captures are processed into counts and dwell figures and then discarded, and no identifier is retained that would link a measurement back to a specific phone. Identifiers are stored only when a visitor explicitly opts in (for example by logging into guest Wi-Fi), which is a choice the operator can simply decline to offer. The system sees journeys, not faces, and it sees them without keeping anything that could be used to recognise the same phone next week.
Where this architecture earns its place in the stack is dwell at the screen. Counting how many people had an opportunity to see a screen is one job, but measuring how long they actually stayed in front of it is the closer proxy for attention, and signal-based dwell measurement at the screen is the cleanest way to get that figure under the EU AI Act and the GDPR.
Architecture 2: door-counter pairing for footfall context
The second architecture does not measure at the screen at all. It measures at the venue's entries and exits, and then weights the screen's audience by the venue's footfall. For a screen inside a transit station, an airport terminal, a shopping centre, or any place-based network, the venue already needs a count of visitors at its doors for its own operations. That people counting feed is a natural input for screen-level audience measurement, and it does not require any sensor on the screen itself.
The technical method at the door is Time-of-Flight depth sensing. A ceiling-mounted sensor fires infrared pulses, measures how long they take to return, and uses that to read the height and shape of whatever passes below it to roughly 30 centimetres. It counts every visitor crossing the threshold, including people not carrying a phone, and it reads geometry rather than images. There is nothing to recognise and no picture to store. For a busy entry the count is continuous, exportable, and audit-friendly.
What pairing buys you is footfall context that no screen-mounted sensor can produce. The screen's audience model can be calibrated against the venue's actual visit count: how many people came in today, what share of them pass the zone that contains the screen, and how that share varies by daypart. This is particularly useful for operators reporting against a currency body's audience methodology, where the per-face impression is computed from a model that needs a venue-level visit input. The door count is exactly that input, produced under a no-personal-data design.
Door-counter pairing on its own does not measure dwell at the screen, and it does not tell you whether visitors who passed the screen actually stopped. It is the footfall layer. It works best combined with one of the other architectures here.
Architecture 3: device-anonymous dwell sampling
The third architecture sits between the first two. It samples dwell at the screen, but it does so without retaining any device identifier and without recognising the same visitor across sessions. The output is a distribution of dwell times in the screen's coverage zone, not a per-person trace.
There are two practical ways to implement it. The first is to take the signal-pattern method described in Architecture 1 and aggressively cap retention: detect a device entering the zone, time how long it stays, record the dwell value, and discard the detection without persisting any identifier or hash that would link to a future detection. The second is to use the Time-of-Flight sensor from Architecture 2 and place it above the screen's coverage zone rather than at a door, so it measures how long people stay in front of the screen by reading their position over time as geometry. Neither variant produces an image, and neither produces a device identifier that survives the session.
What you give up with this architecture is cross-session continuity. You cannot say a visitor who saw the screen on Monday also saw it on Thursday, because the system was specifically designed not to know. What you keep is a dwell distribution that can stand up under audit and under the EU AI Act, computed from sampling rather than from tracking. For many DOOH use cases, that distribution is the figure the campaign actually needs.

Architecture 4: inferred audience via media pairing and time of day
The fourth architecture does not require a sensor on or near the screen at all. The audience for a given play is inferred from the playout log, the schedule, and the contextual data the operator already has about the venue. A screen in a transit station at 08:15 on a weekday has a known audience profile (commuters arriving for the morning peak). The same screen at 22:00 has a different profile. A screen at the entrance to a food court at lunchtime has a different profile again. Pairing the playout log with venue-level visit and dwell data, time-of-day patterns, and the venue's published audience profile gives an audience estimate for every play without measuring anyone individually.
This is the part of the standards work that the OOH currency bodies have been formalising. The audience model uses inputs like venue-level visit volumes, dwell at the zone the screen sits in, and the demographic and behavioural profile published for the venue (or computed from aggregate, consented sources). The inputs combine into an opportunity-to-see figure per play, weighted by the audience associated with that play. The screen itself does not see anyone. The inference happens upstream, from data that has already been collected on a no-personal-data basis.
The strength of this architecture is that it scales. It works for networks of screens where putting a sensor on every face is impractical, and it produces an impression figure that maps directly onto the OOH currency models that buyers already trade against. The weakness is that it is an inferred figure, not a measured one. It needs the underlying venue-level data to be honest and current, and it needs the contextual model to be specific to the venue rather than a generic daypart curve. Used in isolation, it is closer to a planning input than to an audit figure. Combined with one of the measured architectures above, it is the layer that makes the rest of the stack scale across a network.
How the four combine in a real network
None of these architectures is the whole stack. A serious DOOH measurement design uses them in combination, with each one doing what it does well.
- Door-counter pairing produces the footfall layer. It tells you how many visitors are in the venue and how they distribute across zones, which is the input the currency model needs to weight per-face impressions.
- Signal-pattern counting at the screen produces dwell. It tells you how long visitors actually stay in front of the screen, which is the closest measured proxy for attention that you can produce without a camera.
- Device-anonymous dwell sampling is the audit-friendly version of that figure. Where the operator wants a stronger statement on retention and on cross-session non-linkage, this variant is the one that holds up under the strictest reading of the EU AI Act and the GDPR.
- Inferred audience via media pairing produces the per-play impression. It uses the footfall and dwell inputs above, combined with the playout log and the venue's audience profile, to produce the impression figure the buy is actually traded against.
The combination produces a complete measurement stack: a measured footfall input at the door, a measured dwell input at the screen, an audit-friendly dwell sample where stricter retention is required, and an inferred impression figure that maps onto the way buyers trade DOOH. All four layers are produced under a no-personal-data design.
What an operator should not accept anymore
Reading the four architectures in reverse: there is a clear set of measurement patterns that have moved out of the safe zone in 2026, and an operator or buyer should not accept them without a specific legal opinion.
- Face detection at the screen. Even where the system claims to discard the image after counting, the capture itself is the GDPR event. "We delete it afterwards" is not the same as not collecting it.
- Demographic inference from facial features. This is the central category the EU AI Act constrains in publicly accessible spaces. A measurement system that infers age, gender, or any other protected category from a face is a hard system to defend.
- MAC-address retention from Wi-Fi probes. An older generation of DOOH measurement sniffed Wi-Fi probe requests and kept the MAC addresses as device identifiers. Modern phones randomise MACs, the GDPR treats persistent device identifiers as personal data, and the practical answer is to design the system not to retain the MAC at all.
- "Anonymised" downstream of capture. The argument that a camera feed is fine because it is anonymised after the fact is structurally weaker than not capturing the feed in the first place. The cleanest design has nothing identifying to anonymise.
How Ariadne fits
Ariadne builds Architectures 1 and 2 into one sensor unit, and feeds the data into Architectures 3 and 4 at the platform layer. Nothing identifying is captured at any point.
Ariadne measures this with Hybrid Fusion, its patented camera-free method. Time-of-Flight depth sensing counts every visitor at the entrances, capturing geometry rather than images, while patented phone signal sensing follows movement through the interior, detecting the signals a phone emits even in airplane mode. The sensor streams both feeds to Ariadne, where Hybrid Fusion combines them into one trajectory per visit and computes counts, dwell, and paths. The streams carry no identifier: no MAC address, no device ID, no biometric data, and no camera is involved. Identifiers are stored only when a visitor explicitly opts in, which keeps the method GDPR-friendly and outside biometric territory.
For a DOOH operator, that maps onto the four architectures directly. The Time-of-Flight depth sensor handles the footfall layer at the venue's doors and the entries to zones that contain screens, counting every visitor and reading geometry rather than images. The patented phone signal sensing handles dwell in the zones where the screens are, including the screen's own coverage zone, without capturing MAC addresses by default. The fusion happens centrally in the Ariadne platform, not on the sensor, so the per-screen audience and dwell figures the operator reports are produced from streams that carry no identifier. The result is the inputs the standards bodies and the buyers ask for (visits, dwell, opportunity-to-see at the screen) produced under a design that holds up under the GDPR and the EU AI Act. The hardware sits in the Ariadne sensor lineup, reporting goes through visitor marketing analytics, and the data handling is set out in the privacy policy.
A buyer checklist for camera-free DOOH measurement
If you are specifying or auditing measurement on a DOOH buy, and you want a defensible position under the GDPR and the EU AI Act, these are the questions worth putting to the operator and to the measurement provider in writing.
- Is there a camera anywhere in the measurement path? A clean answer is no. Where a camera is present for other reasons (security, queue management), confirm it is not feeding the DOOH measurement stack.
- Does the system detect or infer demographic categories? Under the EU AI Act, demographic inference from facial features in publicly accessible spaces is the constrained case. The answer should be no.
- What identifiers does the system retain? Ask specifically about MAC addresses, device IDs, and hashed identifiers that would let the system recognise the same phone across sessions. A no-personal-data design retains none of these by default.
- Where does the audience figure actually come from? Confirm which of the four architectures above produces each metric: footfall from a door counter, dwell from a screen-level sensor, sampling for the audit-friendly version, or inference from the playout log and the venue's audience profile.
- How long is raw data retained? The cleanest design discards the raw sensor data and keeps only the aggregate counts. Ask for the retention policy in writing, not just the summary.
- Has the design been reviewed under the EU AI Act, not only the GDPR? The two frameworks ask different questions. A system that clears the GDPR on PII grounds can still trip the AI Act on biometric categorisation grounds.
FAQ
Does DOOH measurement require cameras?
No. Ariadne counts with Hybrid Fusion: Time-of-Flight depth sensing plus patented phone signal sensing, never cameras. Time-of-Flight captures geometry rather than images, and signal sensing captures no MAC address by default, so the measurement involves no video, no faces, and no biometric data.
The four architectures in this post produce the audience and dwell figures DOOH needs without a camera and without face detection at any point.
Is camera-free DOOH measurement GDPR-compliant by default?
It can be, and the reason is structural: a method that captures no images, no faces, and no device identifiers by default is not processing personal data, so the heaviest GDPR obligations do not attach to it. That is a stronger position than masking a camera feed after the fact, because there is nothing identifying captured in the first place. The EU AI Act adds a second layer specifically on biometric categorisation; an architecture that does not infer demographic categories from facial features is in a clean position under that Act as well. Confirm the specifics with your own legal team, but a no-personal-data, no-biometric-inference design is the easiest case to make to one.
What about MAC-address tracking from Wi-Fi probes?
Older Wi-Fi-based DOOH measurement sometimes retained MAC addresses as device identifiers. Modern phones randomise MAC addresses, and the GDPR treats persistent device identifiers as personal data. The practical 2026 answer is to design the system not to retain the MAC at all: the signal-pattern method described in this post counts devices and measures dwell without storing a MAC by default. Identifiers are stored only when a visitor explicitly opts in.
Can a DOOH network produce demographic reporting without a camera?
Yes, but it has to be done at the venue level rather than the face level. Demographic context comes from the venue's audience profile (the same kind of data that drives the OOH currency models), combined with time-of-day patterns and venue-level visit data. That gives an audience estimate per play without inferring demographics from any individual visitor's face. Per-face demographic inference is exactly what the EU AI Act constrains, so the venue-level approach is the one that holds up.


